







# Spring AI + Ollama 零基础实战:5分钟搭建RAG问答与Graph Agent,提升AI开发效率
从下面这张图可以快速理解这个工具的核心使用方式:
如果你正在开发AI应用,却卡在“怎么让大模型用上自己的知识库”这个问题上,那你一定对RAG(检索增强生成)不陌生。过去搭建一套完整的RAG系统,需要配置Elasticsearch、Milvus等外部向量数据库,还要处理文档分块、向量化、检索逻辑等一系列工程问题,光是环境搭建就能劝退一半的开发者。
但Spring AI + Ollama这套组合正在改变这个局面。它把本地大模型运行、文档向量化、RAG问答、甚至Agent工作流全部整合到Spring生态中,开发者只需要写几十行Java代码,就能跑通一个完整的智能问答系统。更关键的是,整个过程完全本地化运行,不需要调用任何外部API,数据安全性和响应速度都有保障。
这篇文章会从零开始,带你走通Spring AI + Ollama搭建RAG问答与Graph Agent的完整流程。我会把代码拆开讲清楚每一行在做什么,也会指出那些文档里不会写的坑——比如版本兼容性问题、API差异、以及实际开发中最容易踩的雷区。
为什么Spring AI + Ollama值得关注
先聊一个现实问题:大模型落地最大的障碍是什么?不是模型能力不够,而是“怎么用起来”。
企业级AI应用通常需要三个能力:知识库问答(让模型回答基于内部文档)、工具调用(让模型能查天气、查数据库)、工作流编排(让模型能自主规划步骤)。过去这三件事需要分别对接不同的框架和中间件,维护成本极高。
Spring AI的出现,相当于给Java开发者提供了一套统一的AI开发抽象层。它封装了ChatClient、VectorStore、Advisors等核心组件,让开发者可以用Spring Boot的方式去写AI代码。而Ollama则解决了模型部署的问题——你不需要买GPU服务器,不需要配置复杂的推理环境,本地跑一个docker容器就能用上qwen2.5:7b这样的模型。
这套组合最吸引人的地方在于:开发体验和Spring生态完全一致。如果你写过Spring Boot应用,那学习Spring AI的成本几乎为零。配置、注入、注解、AOP,全是熟悉的配方。
技术栈与核心概念速览
在开始写代码之前,先搞清楚几个关键组件各自负责什么:
| 技术组件 | 说明 |
|———|——|
| Spring AI 1.1.2 | Java AI集成框架,提供ChatClient、VectorStore、Advisors等核心抽象 |
| Ollama | 本地大模型运行时,部署qwen2.5:7b(对话)和nomic-embed-text(向量化) |
| SimpleVectorStore | Spring AI内置内存向量库,开发阶段使用,支持文件持久化 |
| Tika DocumentReader | 自动识别PDF、Word、TXT等格式的文档读取器 |
| QuestionAnswerAdvisor | RAG核心Advisor,自动检索向量库并将结果注入对话上下文 |
| Agent / Graph | 智能体:能够自主决策、规划步骤、调用外部工具的自治系统;Graph是其工作流编排方式 |
这里有一个很多人容易忽略的点:Spring AI的SimpleVectorStore是内存向量库,这意味着重启应用后数据会丢失。不过它支持文件持久化,开发阶段完全够用。如果你要上生产环境,可以替换为Milvus或Pgvector,但那是后话了。
RAG的核心流程:四步走
RAG的本质是“先检索,再生成”。具体到Spring AI的实现,流程分为四步:
- 文档加载与分块:用Tika DocumentReader读取PDF、Word、TXT等文件,然后用TokenTextSplitter按语义切分成小块
- 向量化与存储:调用Ollama的nomic-embed-text模型,把文本块转成向量存入SimpleVectorStore
- 语义检索:用户提问时,把问题也向量化,在向量库中搜索最相似的Top-K个文本块
- 增强生成:把检索到的文本块作为上下文,连同用户问题一起发给大模型,让模型基于知识库内容生成答案
这个流程看起来简单,但实际开发中有几个容易出问题的地方。比如文档分块的粒度——块太小会丢失上下文,块太大又会影响检索精度。Spring AI的TokenTextSplitter默认按token切分,对中文的支持比按字符切分好很多,但chunkSize的取值需要根据你的文档类型调整。
环境准备:Ollama部署与模型下载
在写Java代码之前,先把Ollama跑起来。如果你还没装Ollama,去官网下载安装包,或者用docker:
PR0
然后拉取两个模型:
PR1
这里有个小建议:qwen2.5:7b-instruct的instruct版本专门针对指令跟随优化,比base版本更适合RAG场景。如果你机器配置一般,也可以换成qwen2.5:3b,效果差一些但速度更快。
验证模型是否正常运行:
PR2
看到两个模型都在列表里,说明环境准备好了。
项目搭建:pom.xml完整配置
创建一个Spring Boot项目,Java版本要求17以上。pom.xml的核心依赖如下:
PR3
版本兼容性是个大坑。Spring AI 1.1.2要求Spring Boot 3.4.x,如果你用3.3.x会报各种奇怪的错误。另外,spring-ai-advisors-vector-store这个依赖在1.0.0-M1版本中还不存在,是1.1.0之后才加入的,如果你搜到旧教程用了不同的包名,注意区分。
application.yml配置
PR4
temperature设为0.3是RAG场景的推荐值。温度越低,模型越倾向于确定性输出,减少幻觉。如果你做创意写作,可以调高到0.7以上,但RAG场景下,我们更希望模型严格基于检索到的知识回答。
核心代码实现:从文档加载到向量存储
VectorStoreConfig – 文档加载与持久化向量库
PR5
这段代码有几个关键点:
- Tika DocumentReader会自动识别文件类型,支持PDF、Word、TXT、Markdown等格式。你只需要把文件放在resources/knowledge-base/目录下,它会自动处理。
- TokenTextSplitter的chunkSize设为300,这个值适合中文文档。如果文档是英文,可以适当调大到500。太小会导致上下文碎片化,太大则检索精度下降。
- withKeepSeparator(true) 保留原文的换行和分隔符,这对代码文档和结构化文本很重要。
一个常见误区:文档加载失败
很多新手会遇到Tika读取文档时报错,最常见的原因是文件路径写错。注意@Value("classpath:knowledge-base/badao-internal.txt")中的路径是相对于resources目录的。如果你把文件放在resources根目录,应该写成classpath:badao-internal.txt。
另一个坑是文件编码。Tika默认用UTF-8读取,如果你的文档是GBK编码,需要手动指定编码。不过大多数现代编辑器都默认UTF-8,这个问题不常见。
轻量Agent实现:工具调用模式
Spring AI实现Agent有两种方式。第一种是工具调用模式,也是最简单的方式——直接在ChatClient上注册工具,大模型会根据用户问题自主判断是否需要调用工具。
AgentRagConfig – 注册工具与RAG Advisor
PR6
这里的关键是QuestionAnswerAdvisor,它是RAG的核心组件。它会自动拦截用户请求,去向量库检索相关文档,然后把检索结果注入到对话上下文中。整个过程对开发者透明,你只需要配置好检索参数。
similarityThreshold(0.7) 是相似度阈值,只有相似度超过0.7的文档才会被检索到。这个值需要根据你的数据质量调整。如果文档质量高、内容集中,可以设高一些(0.8);如果文档内容分散,设低一些(0.5)能提高召回率。
WeatherTool – 天气工具类
PR7
@Tool注解是Spring AI 1.1.0之后引入的新API。旧版本用的是@ToolCallback,写法完全不同。如果你看到网上教程用@ToolCallback,注意那是旧版API,1.1.0之后已经废弃了。
这个工具类模拟了天气查询,实际开发中可以对接真实天气API。工具的描述信息很重要,大模型会根据描述判断什么时候调用这个工具。描述写得越清晰,模型调用工具的准确率越高。
Graph编排型Agent:复杂多步推理
工具调用模式适合简单的“一问一答”场景,但如果你需要更复杂的推理流程——比如“先检索知识库,如果没找到就调用外部工具,最后综合生成答案”——就需要用Graph编排来实现。
AgentGraphConfig – Graph工作流实现
PR8
这段代码用Java直接实现了Graph的三个节点:检索节点 → 条件分支 → 生成节点。核心逻辑是:
- 先用向量库检索相关文档
- 如果检索结果为空,自动调用天气工具
- 把检索结果和工具调用结果一起拼成prompt,发给大模型生成最终答案
这是Spring AI目前最灵活的实现方式。虽然官方提供了StateGraph API,但1.1.2版本中StateGraph还在实验阶段,API不稳定。用Java代码直接实现工作流反而更可控,也更容易调试。
一个进阶技巧:prompt模板优化
上面代码中的buildPrompt方法用了简单的字符串拼接。实际开发中,你可以用Spring AI的PromptTemplate来管理prompt模板,支持变量替换和模板复用。比如:
PR9
这样做的好处是prompt和代码分离,方便后续调整和A/B测试。
Service与Controller:暴露API接口
AgentService
PR10
RagController
PR11
这里用Java 17的record来定义请求和响应体,代码简洁很多。如果你还在用Java 11,需要改成传统的getter/setter。
测试验证:看看效果
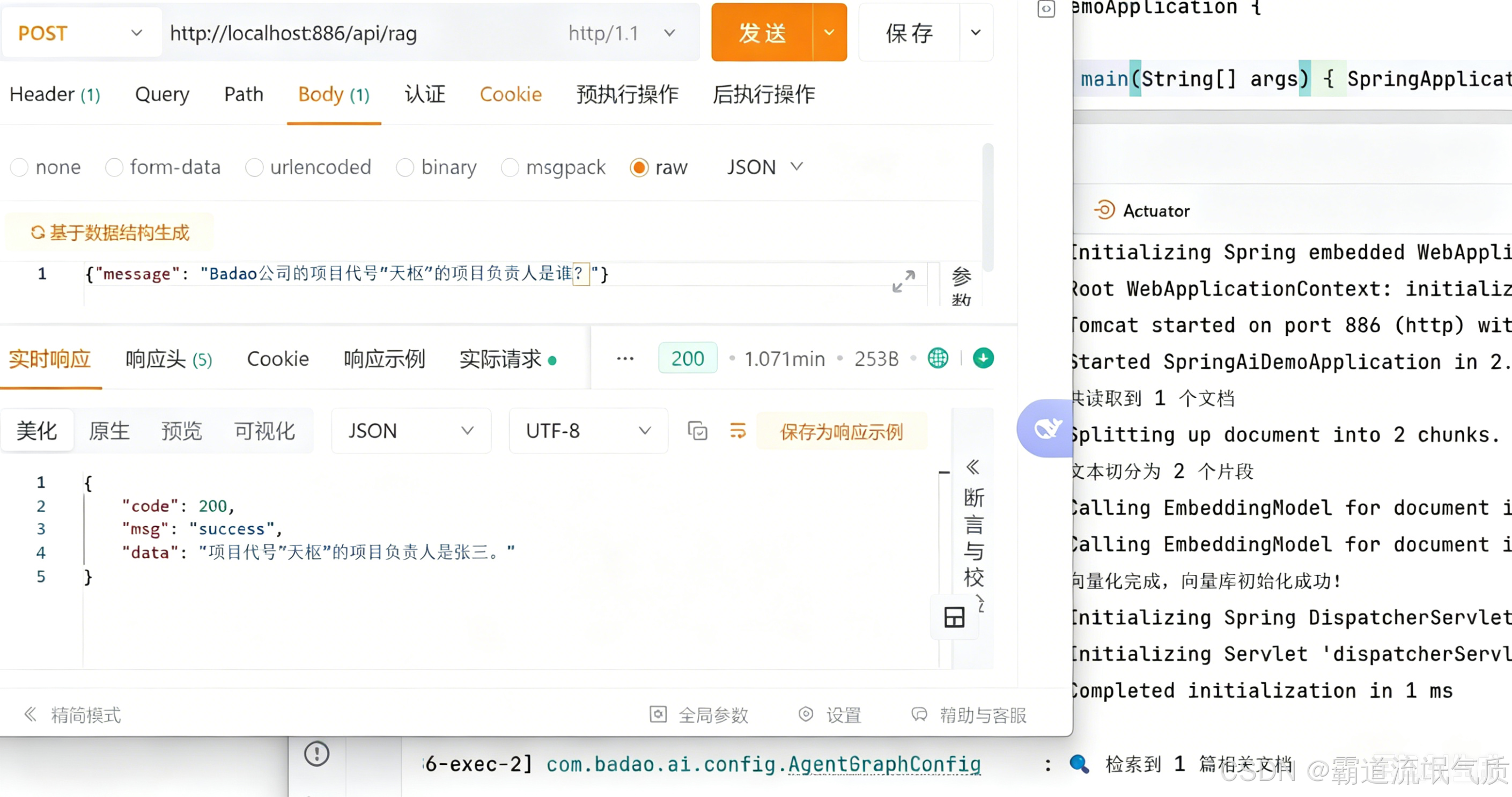
启动应用后,用curl或者Postman发送请求。
测试1:知识库内问题
PR12
如果知识库中有相关文档,会直接返回基于文档的答案。
测试2:知识库外问题
PR13
日志中会清晰看到“检索到0篇相关文档 → 调用天气工具”的节点转换过程。最终返回的答案会包含天气信息。
使用误区与避坑指南
误区1:认为SimpleVectorStore可以用于生产
SimpleVectorStore是内存向量库,重启后数据丢失。虽然它支持文件持久化(通过SimpleVectorStore.builder(embeddingModel).withPath("vectorstore.json").build()),但性能和数据安全性都不够。生产环境建议用Milvus、Pgvector或Elasticsearch。
误区2:忽视模型选择对RAG效果的影响
qwen2.5:7b-instruct在中文场景下表现不错,但如果你处理的是英文文档,换成Llama 3.1或Mistral效果更好。另外,embedding模型的选择也很关键,nomic-embed-text是通用型,如果你处理的是代码或技术文档,可以考虑用专门的代码embedding模型。
误区3:chunkSize一刀切
不同文档类型需要不同的分块策略。技术文档可以分大块(500-800 token),因为上下文关联性强;FAQ类文档适合小块(100-200 token),因为每个问答独立。建议针对不同文档类型配置不同的分块参数。
行业趋势:为什么这类工具越来越多
2024年到2025年,AI开发工具正在经历一次明显的“去中心化”趋势。过去,AI能力被锁定在云端API中,开发者必须依赖OpenAI、Claude等第三方服务。但Ollama、Spring AI这类工具的出现,让本地化AI部署成为可能。
这种变化背后有几个驱动力:
- 数据安全:企业越来越不愿意把内部数据送到云端处理,本地化部署成为刚需
- 成本控制:API调用按量计费,高频使用场景下成本不可控;本地部署只有硬件成本
- 延迟优化:本地推理的响应时间通常在100-500ms,远低于云端API的1-3秒
- 模型进步:开源模型的能力已经接近闭源模型,7B参数级别的模型就能满足大部分业务场景
Spring AI在这个趋势中找到了自己的定位——它不是最前沿的AI框架,但它是最符合Java开发者习惯的AI框架。对于存量Java项目来说,引入AI能力不需要重构技术栈,这是它最大的优势。
如果你正在筛选类似工具,可以参考「国强导航 – 爱国主题实用工具网址大全 – 高效、便捷、更新快」进行系统对比。
使用建议:谁适合用,谁不适合
推荐使用
- Java技术栈的团队:如果你团队的主力语言是Java,Spring AI是最自然的选择
- 需要本地化部署的企业:数据安全要求高,不能使用云端API的场景
- 快速原型验证:从零到跑通RAG流程只需要半天,适合做技术验证
- 中小规模知识库:文档数量在几千篇以内,SimpleVectorStore够用
不推荐使用
- Python技术栈的团队:LangChain和LlamaIndex生态更成熟,社区资源更多
- 超大规模知识库:百万级文档的场景,需要Elasticsearch或Milvus等专业向量数据库
- 需要多模态能力:Spring AI目前主要支持文本,图像和音频支持还在完善中
- 追求最新模型:Spring AI的模型适配有一定滞后性,新模型出来需要等版本更新
总结:是否值得长期使用
Spring AI + Ollama这套组合,解决了一个很实际的问题:让Java开发者用最少的代码量,跑通本地化AI应用。它不需要你懂深度学习,不需要你配置复杂的分布式系统,甚至不需要你买GPU——一台普通开发机就能跑起来。
从长期来看,Spring AI的价值在于它把AI能力变成了Spring生态的一个标准组件。就像Spring Boot让Java Web开发变得简单一样,Spring AI正在做同样的事情——让AI开发变得简单。虽然它目前还在快速迭代中,API变动频繁,但方向是对的。
如果你正在寻找一个低门槛、高可控、与现有技术栈兼容的AI开发方案,Spring AI + Ollama值得投入时间学习。它可能不是最终的生产方案,但绝对是理解RAG和Agent工作流的最佳起点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...